堆(heap)
什么是堆?
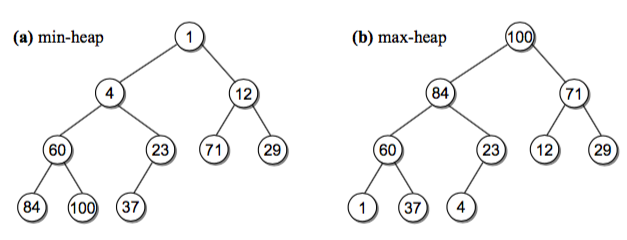
堆是一种完全二叉树(请你回顾下上一章的概念),有最大堆和最小堆两种。
- 最大堆: 对于每个非叶子节点 V,V 的值都比它的两个孩子大,称为 最大堆特性(heap order property) 最大堆里的根总是存储最大值,最小的值存储在叶节点。
- 最小堆:和最大堆相反,每个非叶子节点 V,V 的两个孩子的值都比它大。
堆的操作
堆提供了很有限的几个操作:
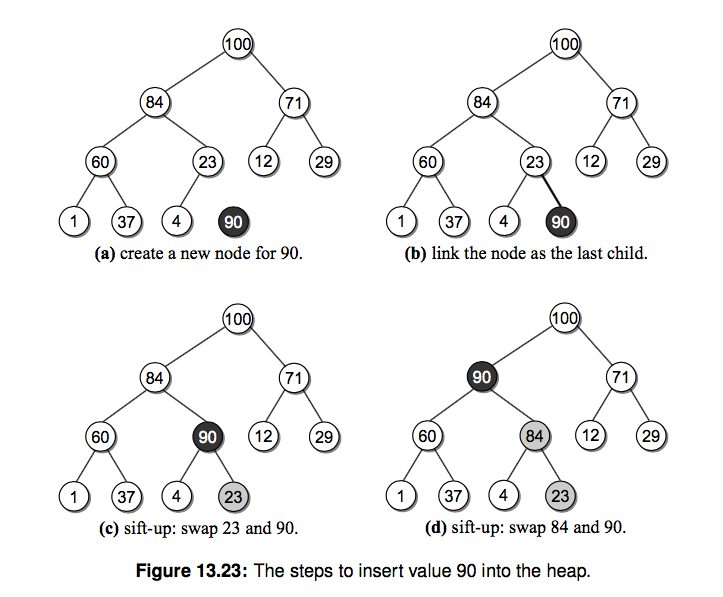
- 插入新的值。插入比较麻烦的就是需要维持堆的特性。需要 sift-up 操作,具体会在视频和代码里解释,文字描述起来比较麻烦。
- 获取并移除根节点的值。每次我们都可以获取最大值或者最小值。这个时候需要把底层最右边的节点值替换到 root 节点之后 执行 sift-down 操作。

堆的表示
之前我们用一个节点类和二叉树类表示树,这里其实用数组就能实现堆。
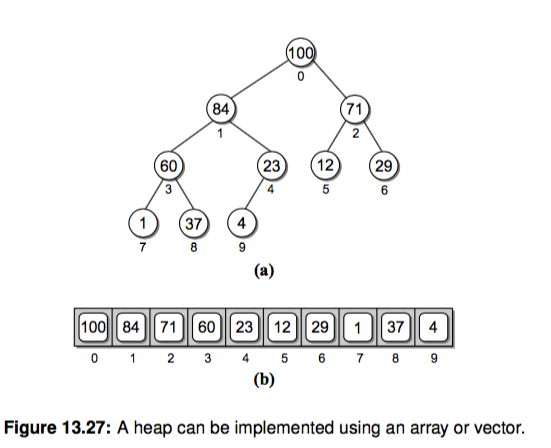
仔细观察下,因为完全二叉树的特性,树不会有间隙。对于数组里的一个下标 i,我们可以得到它的父亲和孩子的节点对应的下标:
parent = int((i-1) / 2) # 取整
left = 2 * i + 1
right = 2 * i + 2
超出下标表示没有对应的孩子节点。
实现一个最大堆
class Heap:
def __init__(self):
self.items = Array(8)
self.count = 0
def add(self, value):
# 根据count来决定将值暂时赋值到哪块空间
self.items[self.count] = value
# 为了保证下一个数据添加时,不替换上一个添加所在的索引的值
self.count += 1
# 将本次添加的数据的索引传到 提权函数中
self.sift_up(self.count - 1)
def sift_up(self, index):
if index <= 0:
return
else:
parent = (index - 1) / 2
if self.items[parent] <= self.items[index]:
self.items[parent], self.items[index] = self.items[index], self.items[parent]
self.sift_up(parent)
def remove(self):
value = self.items[0]
self.count -= 1
self.items[0] = self.items[self.count]
self.items[self.count] = None
self.sift_down(0)
return value
def sift_down(self, index):
left = index * 2 + 1
right = index * 2 + 2
largest = index
if right < self.count:
if self.item[right] > self.item[largest] and self.item[right]> self.item[left]:
largest = right
elif self.item[right] >self.item[largest] and self.item[right] < self.item[left]:
largest = left
elif self.item[right] < self.item[largest] and self.item[left] >self.item[largest]:
largest = left
elif left < self.count:
if self.item[left] > self.item[largest]:
largest = left
if largest != index:
self.item[index],self.item[largest] = self.item[largest],self.item[index]
self.siftdown(largest)
def __iter__(self):
for i in self.items:
if i is not None:
yield i
实现堆排序
上边我们实现了最大堆,每次我们都能 extract 一个最大的元素了,于是一个倒序排序函数就能很容易写出来了:
def heapsort_reverse(array):
length = len(array)
maxheap = MaxHeap(length)
for i in array:
maxheap.add(i)
res = []
for i in range(length):
res.append(maxheap.extract())
return res
def test_heapsort_reverse():
import random
l = list(range(10))
random.shuffle(l)
assert heapsort_reverse(l) == sorted(l, reverse=True)
Python 里的 heapq 模块
python 其实自带了 heapq 模块,用来实现堆的相关操作,原理是类似的。请你阅读相关文档并使用内置的 heapq 模块完成堆排序。 一般我们刷题或者写业务代码的时候,使用这个内置的 heapq 模块就够用了,内置的实现了是最小堆。
Top K 问题(扩展)
面试题中有这样一类问题,让求出大量数据中的top k 个元素,比如一亿个数字中最大的100个数字。 对于这种问题有很多种解法,比如直接排序、mapreduce、trie 树、分治法等,当然如果内存够用直接排序是最简单的。 如果内存不够用呢? 这里我们提一下使用固定大小的堆来解决这个问题的方式。
一开始的思路可能是,既然求最大的 k 个数,是不是应该维护一个包含 k 个元素的最大堆呢? 稍微尝试下你会发现走不通。我们先用数组的前面 k 个元素建立最大堆,然后对剩下的元素进行比对,但是最大堆只能每次获取堆顶 最大的一个元素,如果我们取下一个大于堆顶的值和堆顶替换,你会发现堆底部的小数一直不会被换掉。如果下一个元素小于堆顶 就替换也不对,这样可能最大的元素就被我们丢掉了。
相反我们用最小堆呢? 先迭代前 k 个元素建立一个最小堆,之后的元素如果小于堆顶最小值,跳过,否则替换堆顶元素并重新调整堆。你会发现最小堆里 慢慢就被替换成了最大的那些值,并且最后堆顶是最大的 topk 个值中的最小值。 (比如1000个数找10个,最后堆里剩余的是 [990, 991, 992, 996, 994, 993, 997, 998, 999, 995],第一个 990 最小)
按照这个思路很容易写出来代码:
import heapq
class TopK:
"""获取大量元素 topk 大个元素,固定内存
思路:
1. 先放入元素前 k 个建立一个最小堆
2. 迭代剩余元素:
如果当前元素小于堆顶元素,跳过该元素(肯定不是前 k 大)
否则替换堆顶元素为当前元素,并重新调整堆
"""
def __init__(self, iterable, k):
self.minheap = []
self.capacity = k
self.iterable = iterable
def push(self, val):
if len(self.minheap) >= self.capacity:
min_val = self.minheap[0]
if val < min_val: # 当然你可以直接 if val > min_val操作,这里我只是显示指出跳过这个元素
pass
else:
heapq.heapreplace(self.minheap, val) # 返回并且pop堆顶最小值,推入新的 val 值并调整堆
else:
heapq.heappush(self.minheap, val) # 前面 k 个元素直接放入minheap
def get_topk(self):
for val in self.iterable:
self.push(val)
return self.minheap
def test():
import random
i = list(range(1000)) # 这里可以是一个可迭代元素,节省内存
random.shuffle(i)
_ = TopK(i, 10)
print(_.get_topk()) # [990, 991, 992, 996, 994, 993, 997, 998, 999, 995]
if __name__ == '__main__':
test()